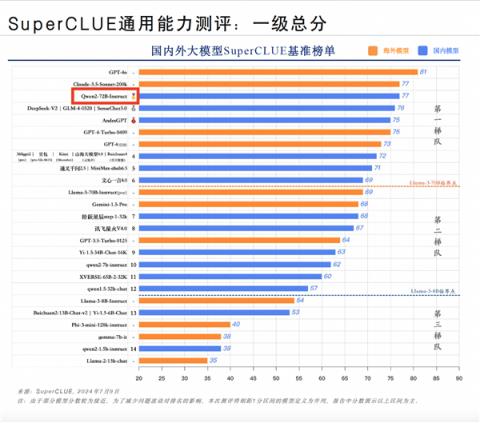
7月10日消息,根据SuperCLUE发布的中文大模型基准测评最新报告,阿里通义千问开源模型Qwen2-72B-Instruct以卓越的表现位居国内通用能力第一,更在全球范围内成为最强开源模型。
SuperCLUE报告详细披露了对国内外33个大模型的综合测评结果,Qwen2-72B在一级总分上以77分的高分与Claude-3.5-Sonnet并列第二,仅次于OpenAI的GPT-4o。
这一得分超越了百度文心一言4.0、讯飞星火V4.0、Llama-3-70B等开闭源大模型。
具体来看,在理科、文科和Hard三个维度的具体测评中,Qwen2-72B展现了全面而均衡的能力。
特别是在理科任务上,Qwen2-72B与GPT-4o的分差仅为5分,显示出其在计算、逻辑推理和代码测评方面的强劲实力。

在文科任务和Hard任务上,Qwen2-72B同样表现不俗,得分均达到了76分,与GPT-4o的得分相差无几。
特别值得一提的是,在端侧小模型测评中,Qwen2-7B以70亿参数的模型规模,超越了上一代320亿参数的Qwen1.5-32B和130亿参数的Llama-3-8B-Instruct,夺得了排名第一的宝座。

这一成绩不仅证明了Qwen2-7B在小尺寸模型中的极致性能,也极大提升了端侧小模型落地的可行性。
数据显示,截至目前Qwen系列模型的下载量已突破2000万次,其应用场景覆盖了工业、金融、医疗、汽车等多个垂直领域。
文章内容举报
本文转载于:快科技,仅供信息分享,无其他用途
© 版权声明
本文中引用的各种信息及资料(包括但不限于文字、数据、图表及超链接等)均来源于该信息及资料的相关主体(包括但不限于公司、媒体、协会等机构)的官方网站或公开发表的信息。部分内容参考包括:(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供参考使用,不准确地方联系删除处理!
THE END